
Contenidos
- Introducción
- Objetivos de la lección
- Nuestros datos: ciudades hermanadas en la Unión Europea
- Ventajas de ggplot2
- Creando tu primer gráfico
- Otros geoms: histogramas, gráficos de dispersión y gráficos de caja
- Manipulaciones avanzadas de la apariencia del gráfico
- Conclusión
- Recursos adicionales
- Notas
Introducción
Después de la Segunda Guerra Mundial, las ciudades europeas se enfrentaron a una tarea monumental: reconstruir no solo su infraestructura física, sino también sus relaciones internacionales. Un enfoque fascinante a través del cual examinar la reconstrucción posbélica es el de las ciudades hermanadas. Estas alianzas formales se desarrollaron entre ciudades en el período de la posguerra para fomentar la cooperación y el entendimiento transfronterizo.
Las relaciones entre ciudades hermanadas enfrentan a los historiadores con oportunidades y desafíos. La oportunidad radica en su potencial para revelar patrones de reconciliación y diplomacia posbélica. El desafío proviene de su escala y complejidad: hay cientos de ciudades en Europa y cada una podría haber formado decenas de acuerdos de hermanamientos a lo largo de múltiples décadas. Al convertir estas complejas redes de relaciones de hermanamiento en patrones visuales, podemos explorar preguntas difíciles de responder únicamente con métodos tradicionales. Por ejemplo, ¿prefirieron las ciudades de Alemania Occidental establecer relaciones con ciudades francesas inmediatamente después de la guerra? ¿Creó el Telón de Acero patrones distintos de relaciones entre Europa del Este y del Oeste? ¿Cómo influyeron el tamaño de la ciudad y la distancia geográfica en las conexiones diplomáticas? Este caso es un buen ejemplo de cómo puede ser útil la visualización de datos para la investigación histórica.
El paquete de R ggplot2 (en inglés) proporciona herramientas poderosas para investigar preguntas de esta índole a través de la visualización de datos. Aunque las hojas de cálculo y los gráficos básicos pueden ocultar patrones, las capacidades de visualización avanzadas de ggplot2 permiten a los historiadores descubrir relaciones ocultas en los datos. Por ejemplo, los gráficos de dispersión pueden revelar correlaciones entre variables numéricas como tamaños poblacionales y distancias geográficas, los gráficos de barras pueden mostrar la distribución de los hermanamientos en diferentes categorías de ciudades, y los histogramas pueden exponer patrones en los datos demográficos que de otro modo podrían permanecer invisibles.
Esta lección se diferencia de las guías estándar de ggplot2 porque se enfoca específicamente en las necesidades de los historiadores urbanos. En lugar de utilizar conjuntos de datos generales, trabajaremos con datos históricos sobre relaciones entre ciudades hermanadas para demostrar cómo las técnicas visuales pueden iluminar patrones y procesos históricos. A través de este enfoque, aprenderás a crear visualizaciones que revelen alianzas complejas y hacer que los procesos históricos sean más accesibles a un público más amplio.
Objetivos de la lección
Al final de esta lección, deberás ser capaz de hacer las siguientes cosas con el paquete ggplot2:
- Crear diferentes tipos de gráficos para visualizar datos urbanos y demográficos, incluyendo gráficos de cajas, gráficos de barras para mostrar relaciones entre ciudades y gráficos de dispersión para explorar relaciones entre diferentes variables.
- Manipular la apariencia de los gráficos, como su color o tamaño.
- Agregar etiquetas significativas a los gráficos.
- Comparar datos a través de grillas de gráficos.
- Mejorar tus gráficos con extensiones de ggplot2.
Esta lección supone que tienes conocimientos básicos de R. Recomendamos que te familiarices con las lecciones de Programming Historian Datos tabulares en R y Administración de datos en R.
Nuestros datos: ciudades hermanadas en la Unión Europea
Los datos urbanos y demográficos son fundamentales para comprender el desarrollo de las sociedades humanas. Los datos urbanos nos permiten reconstruir la compleja red de relaciones entre ciudades. Esto abarca desde las conexiones administrativas formales, como las alianzas comerciales o las alianzas políticas, hasta las relaciones informales construidas a través del intercambio cultural y el movimiento de población. Las ciudades pueden estar unidas a través de rutas comerciales, estructuras de gobernanza compartidas o instituciones culturales. Las características físicas de las ciudades también forman una parte importante de los datos urbanos: su ubicación geográfica, su proximidad a otros centros urbanos y su posición en los sistemas de transporte influyen en cómo las ciudades interactúan entre sí.
La información urbana también nos ayuda a comprender los diferentes roles que desempeñan las ciudades en los sistemas sociales y económicos más amplios. Algunas ciudades sirven como centros administrativos, otras como puertos principales que facilitan el comercio internacional y, más aún, otras como centros industriales que impulsan el crecimiento económico. Estos roles a menudo cambian a lo largo del tiempo a medida que las ciudades se adaptan a los cambios políticos, económicos y tecnológicos.
La información demográfica complementa este análisis urbano revelando la dimensión humana del cambio. En su nivel más básico, la información demográfica nos proporciona datos sobre las tasas de población y sus fluctuaciones, pero su verdadero valor radica en ayudarnos a comprender los complejos patrones de movimiento y asentamiento. Los cambios en la densidad poblacional reflejan los procesos de urbanización, las oportunidades económicas o las respuestas a los desafíos ambientales. Los patrones de migración pueden iluminar las relaciones económicas entre regiones, así como el impacto de las políticas públicas. Las características sociales y económicas de las poblaciones —sus distribuciones por edad, patrones ocupacionales y estructuras sociales— también proporcionan un contexto crucial para comprender el desarrollo urbano.
Los historiadores pueden combinar estos tipos de datos para investigar el desarrollo urbano y las dinámicas demográficas. Como se mencionó anteriormente, analizaremos ciudades hermanadas –pares de ciudades que se han unido para promover vínculos culturales y comerciales. El concepto moderno de ciudades hermanadas surgió tras la Segunda Guerra Mundial con el fin de fomentar la amistad y el entendimiento cultural, así como fortalecer el comercio y el turismo. Estas alianzas a menudo implican intercambios estudiantiles, relaciones comerciales y eventos culturales. Al examinar estas alianzas, podemos evaluar si la proximidad geográfica, el idioma compartido o un tamaño de población similar tienen influencia en la creación de una relación entre dos ciudades. También podemos explorar si las tensiones, alianzas históricas (como entre Alemania, Francia y Polonia) o lengua compartida (por ejemplo, entre las ciudades hispanohablantes de América) moldean estas alianzas. En los últimos años, los historiadores han comenzado a investigar de manera más cercana estas interacciones (en inglés) desde esta perspectiva.
La primera pregunta es dónde obtener datos sobre ciudades hermanadas. Una posibilidad es acudir a uno de los mayores repositorios de datos del mundo: Wikidata. En Wikidata, cada ciudad posee un identificador único y página asociada con información basica. Por ejemplo, la página dedicada a Londres incluye, entre otros elementos, una lista de sus ‘corporaciones administrativas unidas’ (es decir, sus ciudades hermanadas). Mediante el Protocolo de SPARQL y Lenguaje de Consulta RDF (en inglés), es posible consultar y extraer información sobre las ciudades asociadas con Londres. Como en toda investigación histórica, es importante considerar la precisión de los datos, algo que ha sido analizado varias veces (en inglés) en el caso de Wikidata.
Para los objetivos de este estudio, desarrollamos diversas consultas destinadas a extraer datos sobre ciudades en la Unión Europea (UE) y sus ciudades hermanadas. Construimos un conjunto de datos que incluye: el nombre, el país, el tamaño de la población y las coordenadas geográficas tanto de la ‘ciudad de origen’ como de la ‘ciudad destino’. Además, calculamos la distancia entre cada par de ciudades, y agregamos una columna de dato lógico (booleano) indicando si la ciudad destino está dentro de la Unión Europea o no (todas las ciudades de origen se encuentran dentro de la UE). Puedes descargar este conjunto de datos desde el repositorio de Programming Historian.
Nuestra aproximación es fundamentalmente exploratoria, con el objetivo de identificar patrones, tendencias y relaciones en los datos. Esperamos poder descubrir nuevos enfoques y generar hipótesis para investigaciones futuras más profundas.
Ventajas de ggplot2
Tenemos muchas razones por qué elegir ggplot2 para este análisis. El paquete tiene un gran número de ventajas frente a otras alternativas:
- Se basa en un marco teórico (detallado a continuación) que asegura que tus gráficos transmitan la información de forma significativa lo cual es particularmente importante cuando se trabaja con conjuntos de datos urbanos y demográficos complejos.
- Es relativamente sencillo de utilizar a pesar de su potencia.
- Crea gráficos listos para su publicación.
- Viene con extensiones desarrolladas por la comunidad ggplot2 extensions que lo enriquecen aún más, como funciones adicionales, gráficos y temas.
- Es versátil, y puede trabajar con distintas estructuras de datos como
- Datos numéricos (continuos y discretos)
- Datos categóricos (factores y cadenas de caracteres)
- Datos de fecha y hora
- Coordenadas geográficas
- Datos de texto
Crear gráficos es una tarea compleja, ya que nos obliga a considerar varios aspectos de nuestros datos: la información que queremos transmitir, el tipo de gráfico que queremos utilizar para transmitirla (gráfico de dispersión, gráfico de caja, histograma,etc), los elementos del gráfico que queremos ajustar (eje, variables, leyendas), y mucho más. Basado en un marco teórico conocido como la gramática de gráficos (en inglés) (de ahí el ‘gg’ en el nombre ggplot2) (de acuerdo con Leland Wilkinson (en inglés))1, ggplot2 es una herramienta útil para estandarizar estas opciones. Si todo esto suena complicado al principio, no te estreses: solo necesitas saber un poco sobre la gramática para crear tu primer gráfico.
En el lenguaje de los gráficos, toda la composición de las representaciones gráficas se basa en siete capas interconectadas:
- Datos: el material a analizar en la visualización.
- Estética: las formas en que las propiedades visuales se mapean sobre los supuestos ‘geoms’ (ver Objetos geométricos a continuación). En la mayoría de los casos, esto determina cómo deseas mostrar tus datos (posición, color, forma, relleno, tamaño).
- Escala (en inglés): el mapeo y la normalización de los datos para la visualización.
- Objetos geométricos (o ‘geoms’ en el lenguaje de ggplot2): cómo quieres representar tus datos. En la mayoría de los casos, esto determina el tipo de gráfico que usas, como un gráfico de barras, un gráfico de línea o un histograma.
- Estadística (en inglés): los cálculos que se pueden realizar sobre tus datos antes de visualizarlos.
- Facetas: la capacidad de categorizar y dividir los datos en múltiples subgráficos.
- Sistemas de coordenadas (en inglés): cómo ggplot2 coloca diferentes geoms (geometrías) en el gráfico. La coordenada más común es el sistema de coordenadas cartesianas, pero ggplot2 también puede representar coordenadas polares y proyecciones estereográficas.
Para comenzar a utilizar ggplot2, es necesario instalar y cargarlo. Recomendamos instalar tidyverse (en inglés), una colección de paquetes R, entre ellos ggplot2, que trabajan juntos para proporcionar un flujo de trabajo coherente y eficiente a la hora de manipular, explorar y visualizar datos. En el corazón de la filosofía de tidyverse se encuentra el concepto de ‘datos ordenados’ (en inglés), un enfoque estándar que estructura los datos para facilitar el trabajo con ellos. En este tipo de datos, cada variable es una columna, cada observación es una fila y cada tipo de unidad de observación es una tabla. Esta estructura permite un enfoque coherente y predecible al trabajar con datos a lo largo de diferentes paquetes y funciones dentro de la colección tidyverse. Para obtener más detalles, consulta el libro R para Ciencia de Datos escrito por Hadley Wickham et al.2
install.packages("tidyverse")
library(tidyverse)
Cargando datos con el paquete readr
Antes de importar datos, es importante comprender cómo deben estar formateados. Las aplicaciones de hoja de cálculo comunes, como Microsoft Excel o Apple Numbers, guardan los datos en un formato propietario. Aunque existen paquetes que pueden leer datos de Excel, como readxl, se recomienda utilizar formatos abiertos en su lugar, como .csv (valores separados por comas) o .tsv (valores separados por tabuladores), ya que son compatibles con una amplia gama de herramientas de software y es más probable que puedan leerse también en el futuro con cualquier programa.
R tiene funciones internas para leer estos archivos, pero usaremos la biblioteca readr del ecosistema tidyverse, que puede leer la mayoría de los formatos comunes. Para nuestro análisis, leeremos un archivo .csv. Vamos a descargar el conjunto de datos y a colocarlo en el directorio de trabajo actual del proyecto. A continuación, puedes usar read_csv() (en inglés) con la ruta del archivo. (Si no instalaste tidyverse anteriormente, necesitarás cargar manualmente la biblioteca readr primero.)
eudata<-read_csv("ciudadeshermanadas.csv")
Ahora, podemos mostrar los datos como un tibble (13,081 x 15):
eudata
tidyverse convierte nuestros datos en un ‘tibble’ más que un ‘data frame’. Los tibbles forman parte del universo tidyverse y ofrecen la misma funcionalidad que los llamados dataframes, pero toman decisiones sobre cómo importar y mostrar los datos en R. R es un lenguaje de programación relativamente antiguo y, como resultado, las preferencias que se tomaron durante la implementación original son distintas a las preferencias actuales. Los tibbles, al contrario que los dataframes, no cambian los nombres de las variables, no convierten el tipo de entrada ni crean nombres de filas. Puedes aprender más sobre tibbles aquí (en inglés). Si esto no tiene sentido, no te preocupes. En la mayoría de los casos, podemos tratar los tibbles como dataframes y convertir un formato a otro con facilidad. Para convertir tu dataframe a un tibble, utiliza la función as_tibble() con el nombre del dataframe como parámetro. De manera similar, para convertirlo de vuelta a un dataframe, utiliza la función as.data.frame().
Empezaremos explorando los datos para las ciudades en seis países de la Unión Europea: Alemania, Francia, Portugal, Polonia, Hungría y Bulgaria (tres países de Europa occidental y tres de Europa oriental). La tabla que has visto anteriormente, llamada eudata, contiene esta información en 14 variables y 13,081 filas. Con la función glimpse() podemos echarle un vistazo a la estructura de nuestro tibble:
glimpse(eudata)
Rows: 13,081
Columns: 14
Estructura del tibble eudata con las variables y sus tipos:
| Columna | Tipo de datos | Valores de muestra |
|---|---|---|
| origenciudadEtiq | <chr> |
“Veliko Tarnovo”, “Pernik”, “Obzor”, “Balch”… |
| origenpais | <chr> |
“Bulgaria” |
| origenlat | <dbl> |
43.08222, 42.60972, 42.82300, 43.40778… |
| origenlong | <dbl> |
25.63167, 23.03083, 27.87870, 28.16222… |
| origenpoblacion | <dbl> |
71150, 75191, 2125, 12913, 9831, 22022… |
| ciudadhermanaEtiq | <chr> |
“Asti”, “Graz”, “Toledo”, “18th district of Budapest”… |
| destinolat | <dbl> |
44.90000, 47.06667, 39.86667, 47.43333… |
| destinolong | <dbl> |
8.206944, 15.433333, -4.033333, 19.166667… |
| destinopoblacion | <dbl> |
76173, 282479, 83459, 101613, 36119, NA… |
| destinopaisEtiq | <chr> |
“Italia”, “Austria”, “España”, “Hungría”, “Polonia”… |
| dist | <dbl> |
1406, 777, 2484, 853, 854, 1012, 1390… |
| eu | <chr> |
“EU” |
| igualpais | <chr> |
“diferente” |
| tipopais | <chr> |
“EU” |
El tibble contiene información completa que combina datos urbanos y demográficos sobre relaciones de ciudades hermanadas. Los datos urbanos incluyen el nombre de las ciudades de origen y destino (origenciudad, destinociudad), sus respectivos países (origenpais, destinopais) y sus coordenadas geográficas (origenlat, origenlong, destinolat, destinolong). También contiene información sobre la distancia entre las ciudades vinculadas (dist) y el estatus de relación administrativa de cada ciudad (eu). Para el análisis demográfico, contamos con el tamaño de población de ambas ciudades de origen y destino (origenpoblacion, destinopoblacion). Esta combinación de datos permite explorar cómo las características urbanas y los patrones poblacionales influyen en las relaciones entre ciudades.
Creando tu primer gráfico
Empecemos creando un primer gráfico. Analicemos un patrón urbano que se relaciona con cuestiones más amplias sobre la integración europea y las relaciones internacionales: ¿los ayuntamientos de la UE tienden a formar hermanamientos más sólidos con ciudades del mismo país, con ciudades de otros países de la UE o con ciudades fuera de la UE? Al responder a esta pregunta, podemos comprender no solo las relaciones de ciudades hermanadas, sino también procesos históricos más amplios, como la reconciliación tras la guerra, el desarrollo de la identidad europea y la naturaleza cambiante de la diplomacia urbana. Otras técnicas de visualización podrían emplearse para estudiar distintas formas de relaciones internacionales, como alianzas comerciales, intercambios culturales o misiones diplomáticas.
Comenzaremos contando aquellas ciudades hermanadas con otras del mismo país, de otro país dentro de la UE o de un país fuera de la UE. Vamos a introducir el siguiente código:
ggplot(eudata, aes(x = tipopais)) +
geom_bar()
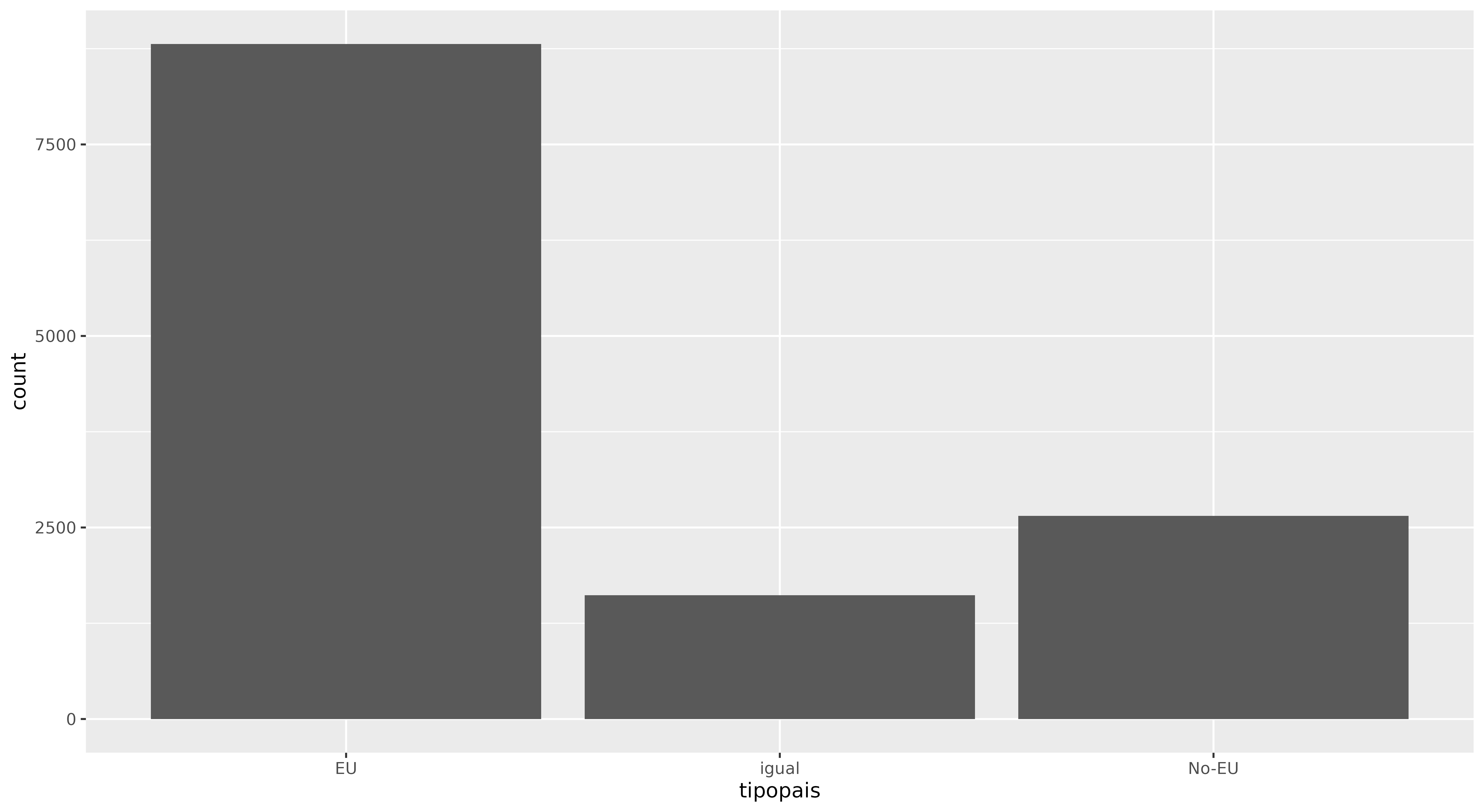
Figura 1. Gráfico de barras que muestra el total de ciudades destino que son nacionales, de la UE, o no de la UE.
El primer parámetro de la función ggplot() son los datos (tibble o dataframe) que contienen la información que se está explorando, mientras que el segundo parámetro son las llamadas ‘estéticas’ del gráfico. Como puedes recordar, las estéticas definen las variables en tus datos e indican cómo quieres mapearlas a las propiedades visuales. Estos dos son los fundamentos de cualquier gráfico.
La capa geom() le dice a ggplot2 qué tipo de gráfico deseas producir. Para crear un gráfico de barras, necesitas la capa geom_bar(), que se agrega utilizando el comando +, como se muestra en el código anterior.
Entender la sintaxis de ggplot() puede ser confuso al principio pero una vez que adquiera sentido, podrás apreciar la potencia del marco estándar que subyace a ggplot2 (la gramática de gráficos). Una forma de pensar en esta gramática es comparar la creación de gráficos con la construcción de una oración. En este ejemplo, le dijiste a R: ‘Crea un gráfico de ggplot utilizando los datos en eudata, mapea el campo tipopais a x y agrega una capa llamada geom_bar()’. Esta estructura es relativamente sencilla. aes() (en inglés) no es tan fácil de explicar, pero su funcion es bastante clara: indica a R que mapee ciertos campos de los datos a las propiedades visuales (estéticas) de los geoms (geometrías) en el gráfico. No te preocupes si no lo entiendes completamente. Volveremos a profundizar más adelante.
¡Ahora tienes tu primer gráfico. Podrás notar que ggplot2 ha realizado algunas decisiones por su cuenta: el color de fondo, el tamaño de la fuente de las etiquetas, etc. Las configuraciones predeterminadas suelen ser suficientes, aunque puedes personalizarlas si lo prefieres.
Dado que ggplot2 funciona dentro de una sintaxis consistente, puedes modificar fácilmente tus gráficos para cambiar su apariencia o los datos que muestran. Por ejemplo, si deseas porcentajes en lugar de conteos simples, puedes crear un nuevo tibble que calcule los porcentajes y agregue los nuevos datos en una nueva columna llamada porcentaje (consulta la lección Administración de datos en R sobre dplyr si este código no te resulta familiar). Luego, solo necesitas ajustar el código para agrupar los datos por tipo de país, agregar una nueva columna con porcentajes y generar el nuevo gráfico:
eudata.porcentaje <- eudata %>%
group_by(tipopais) %>%
summarise(total = n()) %>%
mutate(porcentaje = total/sum(total))
ggplot(data = eudata.porcentaje, aes(x = tipopais, y = porcentaje)) +
geom_bar(stat = "identity")
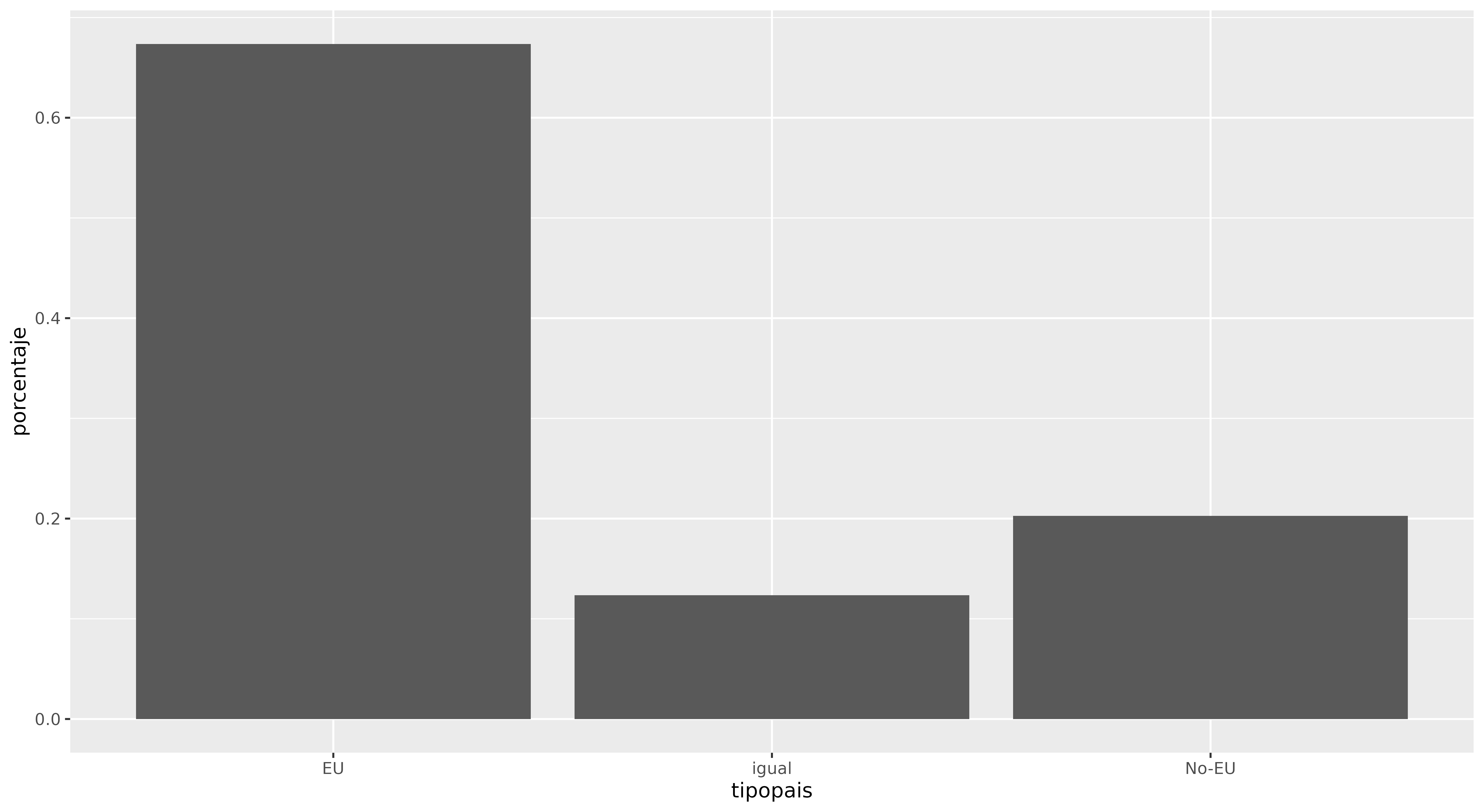
Figura 2. Gráfica de barras que muestra la proporción de ciudades de destino que son nacionales, de la UE y de fuera de la UE.
Hay una diferencia importante entre el primer gráfico (Figura 1) y este. En el primero, ggplot2 contó el número de ciudades en cada grupo (doméstico, UE, no-UE). En el segundo, el tibble ya contiene el valor numérico de cada barra, almacenado en la columna porcentaje. Por esta razón especificamos y = porcentaje como un parámetro de aes() (es decir, aesthetics). De forma predeterminada, geom_bar() utiliza el parámetro stat = "count". Esto significa que contará cuántas veces aparece cada valor. En otras palabras, agrupará los datos para ti. Sin embargo, puedes informar a ggplot2 que ya has calculado tus valores utilizando el parámetro stat = "identity".
El gráfico 2 muestra que la mayoría de las ciudades hermanas son de un país diferente al de origen, aún así dentro de la UE (cerca del 68%). Esto podría deberse a la proximidad geográfica, similitudes culturales o vínculos económicos dentro de la Unión Europea. Puedes obtener más detalle agregando el nombre de cada país de origen al gráfico. Puedes decidir visualizar esto, por ejemplo, dividiendo cada barra en porcentajes por país de origen (gráfico 3), o creando gráficos separados para cada uno (esto se llama ‘faceting’ en el lenguaje ggplot2, que abordaremos más abajo). Intentemos la primera opción, agrupando los datos por país y por tipo de país y agregando una nueva columna con porcentajes:
eudata.porcentaje.pais <- eudata %>%
group_by(origenpais, tipopais) %>%
summarise(total = n()) %>%
mutate(porcentaje = total/sum(total))
ggplot(data = `eudata.porcentaje.pais`,
aes(x = tipopais, y = porcentaje, fill = origenpais)) +
geom_bar(stat = "identity", position="dodge")
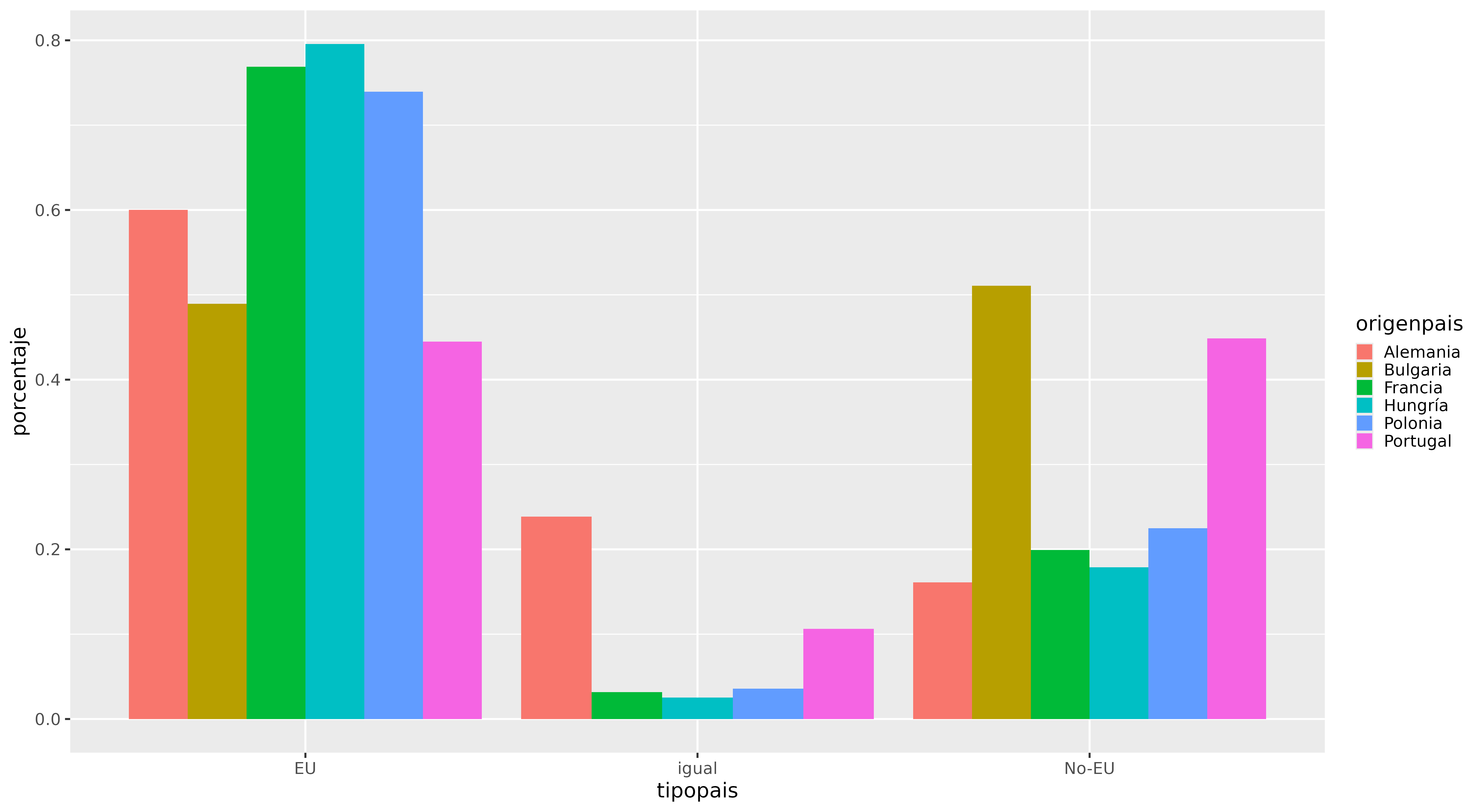
Figura 3. Gráfico de barras con el porcentaje de ciudades de destino que son nacionales, UE y fuera de la UE, con datos agregados por país y tipo de país.
Para este gráfico (Figura 3), hemos creado un tibble que agrupa los datos según el país de origen y el tipo de país de destino (UE, no-UE, nacional). Hemos mapeado la variable origenpais a la estética de relleno (fill) del comando ggplot() que define la gama de colores de las barras. También hemos agregado a geom_bar() el parámetro position con el valor dodge para que las barras no se superpongan (lo cual es el comportamiento predeterminado), sino que se coloquen una al lado de otra.
Ahora que has visualizado las relaciones urbanas (acuerdos entre ciudades), exploraremos cómo estos patrones interactúan con las características demográficas, especialmente la población.
La Figura 3 revela que la mayoría de los países en nuestro análisis (Hungría, Francia, Polonia y Alemania) prefieren establecer fuertes relaciones de ciudades hermanadas con otros países de la Unión Europea, con aproximadamente el 60-80% de sus acuerdos en la UE. Sin embargo, Bulgaria y Portugal difieren de esta tendencia: ambos parecen tener una proporción similar de acuerdos con países de la UE y con países fuera de la UE. Esto sugiere que Bulgaria y Portugal tienen un enfoque más equilibrado hacia la formación de acuerdos tanto dentro como fuera de la Unión Europea.
En el caso de Portugal, este enfoque más global podría atribuirse a su extensa historia colonial, que podría haber fomentado vínculos culturales, lingüísticos y económicos duraderos con ciudades en sus antiguas colonias, como Brasil, Angola y Mozambique.
En cuanto a Bulgaria, se necesitarían investigaciones más a fondo para descubrir los factores que contribuyen a su porcentaje relativamente alto de hermanamientos con ciudades que no son de la Unión Europea. Las posibles explicaciones incluyen su ubicación geográfica en la periferia de la Unión Europea, sus vínculos culturales y lingüísticos con países de los Balcanes y Europa del Este, o sus relaciones económicas con países fuera de la UE.
Mientras que estas primeras observaciones proporcionan un punto de partida para comprender los patrones de relaciones, es esencial profundizar en el contexto histórico, cultural y político de cada país para comprender las razones subyacentes a estas tendencias.
Otros geoms: histogramas, gráficos de dispersión y gráficos de caja
Hasta ahora hemos presentado los elementos clave de la sintaxis para operar con ggplot2: crear capas y agregar parámetros. Una de las capas más importantes es la capa geoms (geometrías). Su uso es bastante directo, ya que cada tipo de gráfico tiene su geom asociado:
geom_histogram()para gráficos de histograma (en inglés)geom_boxplot()para gráficos de caja (en inglés)geom_violin()para gráficos de violin (en inglés)geom_dotplot()para gráficos de puntos (en inglés)geom_point()para gráficos de dispersión (en inglés)
Se pueden configurar fácilmente aspectos de cada uno de estos geoms (geometrías), como su tamaño y color.
Para practicar el uso de estos geoms (geometrías), vamos a crear un histograma para visualizar un aspecto importante de las ciudades hermanadas: la distancia entre ellas. Este aspecto espacial ayuda a entender cómo la proximidad geográfica influye en este tipo de alianzas. Ejecuta el siguiente código para filtrar los datos y visualizar el gráfico. Recuerda cargar tidyverse o dplyr para evitar que la función filter genere un error (pues usaría la función nativa de R base y no la de dplyr). Más concretamente, nuestro filtro va a seleccionar únicamente vínculos en los que las ciudades distan un máximo de 5000 kilómetros.
eudata.filtered <- filter(eudata, dist < 5000)
ggplot(eudata.filtered, aes(x=dist)) +
geom_histogram()
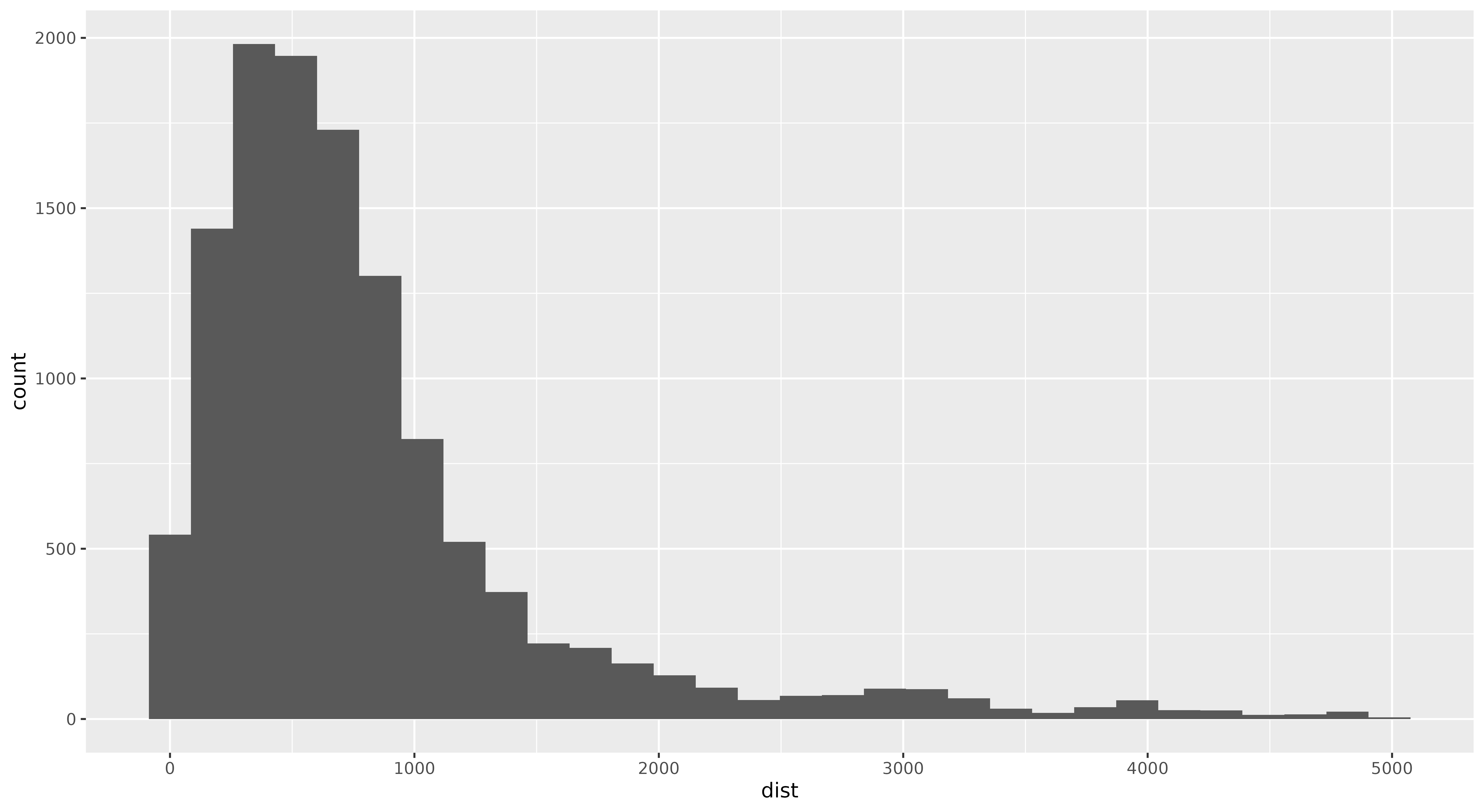
Figura 4. Histograma que muestra las distancias (en logaritmo natural) entre las ciudades hermanadas.
Como muestra el código anterior, solo es necesario agregar geom_histogram() para crear un histograma. Crear un histograma efectivo implica un poco más de trabajo. Es importante, por ejemplo, determinar el tamaño de la celda que da sentido a los datos. El tamaño de esa celda, también conocido como ‘intervalo’ o ‘ancho de banda’, se refiere al ancho de cada barra y determina cómo se agrupan y se muestran los datos a lo largo del eje x. En el gráfico representado en la Figura 4, ggplot2 utilizó un valor predeterminado de 30 (bins=30), pero se muestra un mensaje de advertencia que recomienda elegir un mejor valor. Puedes explorar más posibilidades de configuración en la documentación de geom_histogram() (en inglés).
Este simple gráfico muestra una distribución asimétrica hacia la derecha: la variable dist nos dice que mientras que la mayoría de las ciudades hermanadas tienden a estar geográficamente cerca, existen excepciones en las que las ciudades forman acuerdos con otras más lejanas.
Puedes utilizar una función de distribución acumulativa (FDA) o función de distribución empírica utilizando el conjunto de datos no filtrado para obtener más información sobre este patrón y comprender mejor la distribución espacial de las relaciones de ciudades hermanadas. Piensa en esta FDA como subir una montaña: al igual que el perfil de la montaña revela su forma, la curva de la FDA revela la forma de la distribución de la variable dist. Una distribución asimétrica hacia la derecha se vería como una montaña con una subida inicial rápida (muchas ciudades con distancias cortas) seguida de una pendiente suave hacia la cima (pocas ciudades con distancias largas). Esto confirmaría que la aparente asimetría observada en la variable dist es una característica genuina de cómo las ciudades forman acuerdos. A diferencia de un histograma, que puede cambiar de forma dependiendo de cómo agrupes las distancias, el perfil de la montaña de la FDA permanece constante.
En ggplot2, puedes crear una función de distribución acumulada (FDA) agregando la capa stat_ecdf() a tu gráfico. Ejemplo:
ggplot(eudata, aes(x=dist)) +
stat_ecdf()
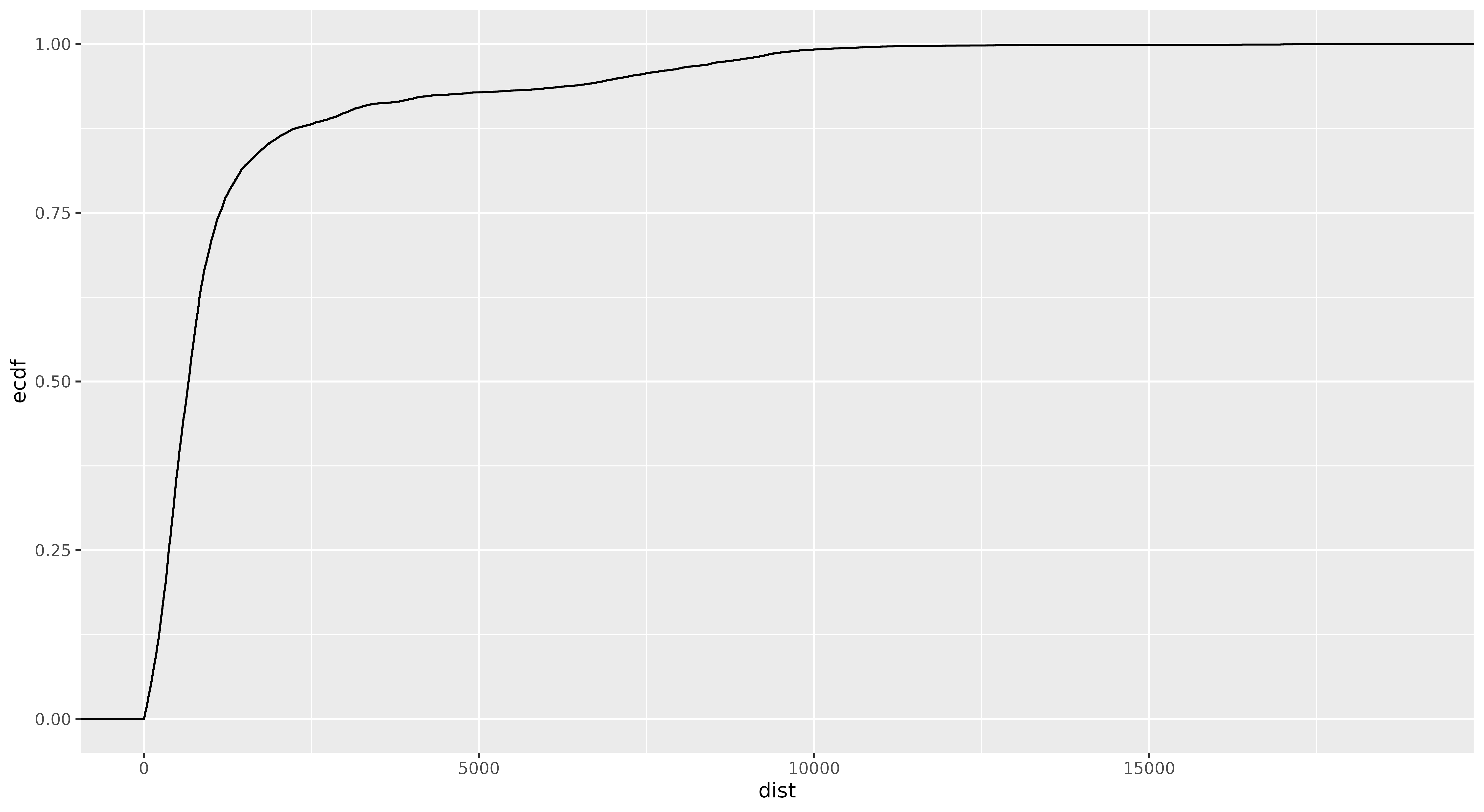
Figura 5. Gráfico ECDF que muestra distancias entre ciudades hermanadas.
Vamos a examinar este gráfico de FDA creado a partir del data frame eudata no filtrado. El gráfico confirma observaciones previas sobre la distribución desigual de las distancias: cerca del 75% de las ciudades tienen relaciones dentro de un radio de alrededor de 1000 kilómetros. Más peculiar aún, alrededor del 50% de las ciudades están conectadas con otras ciudades que se encuentran a menos de 500 kilómetros.
Por último, crearemos un gráfico de cajas para comparar cómo diferentes países estructuran sus relaciones en el espacio. Esta visualización permite observar si algunos países tienden a formar redes urbanas más localizadas mientras que otros mantienen conexiones geográficas más extensas. Al comparar la distribución de distancias, pueden identificarse patrones nacionales en la forma en que las ciudades construyen sus vínculos internacionales.
ggplot(eudata.filtered, aes(x = origenpais, y = dist)) +
geom_boxplot()
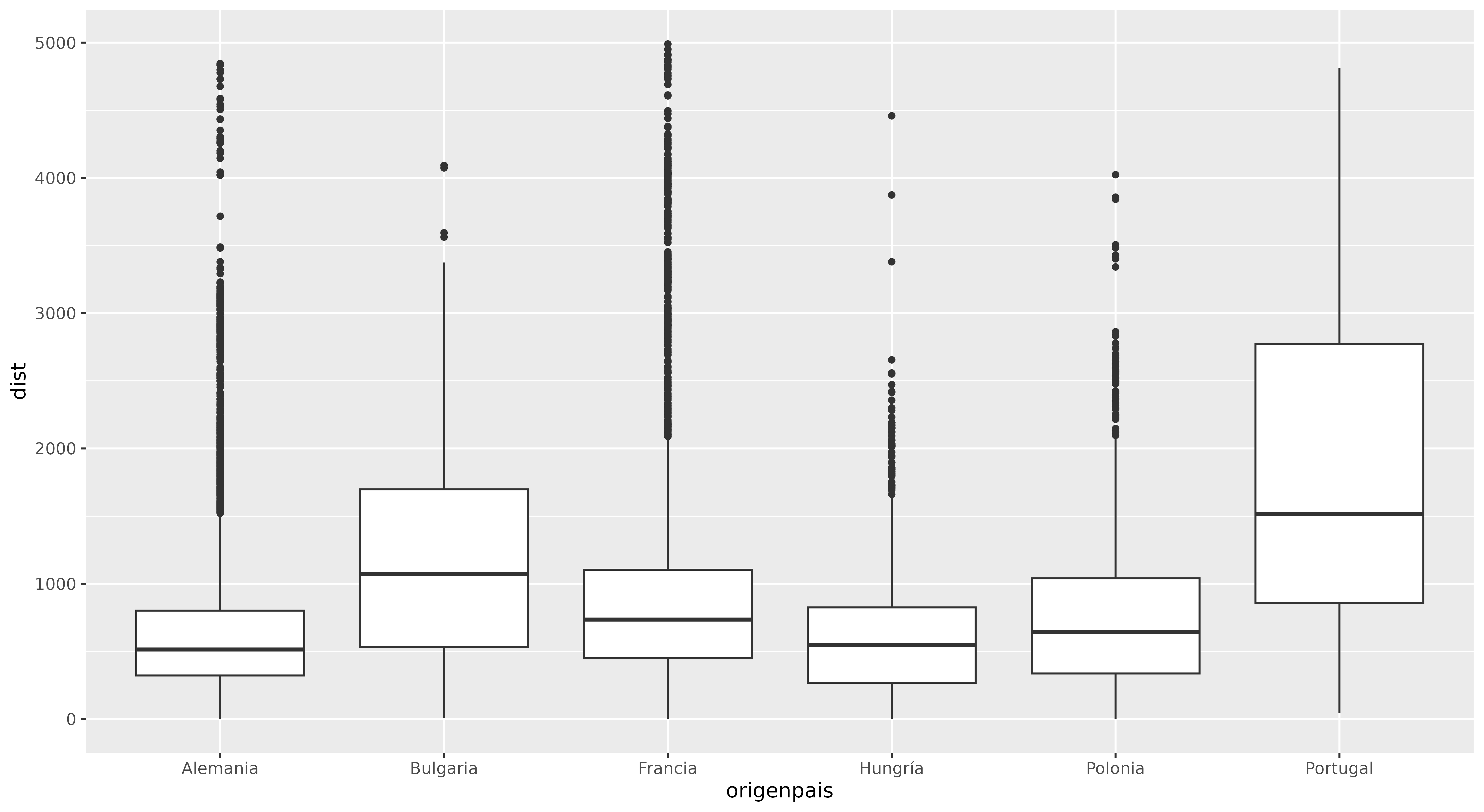
Figura 6. Gráfico de cajas con distancias (en kms) entre ciudades hermanadas agrupadas por países..
El gráfico 6 revela un patrón interesante en el caso de las ciudades alemanas: estas tienden a establecer hermanamientos con ciudades geográficamente más cercanas, según indican tanto los valores promedio más bajos como la menor dispersión observada en la caja respecto de otros países. Esto podría reflejar la posición de Alemania como país central y bien conectado dentro de la Unión Europea, con una posición geográfica destacada y estrechas relaciones económicas con sus vecinos, factores que pueden favorecer la formación de alianzas regionales a menor distancia.
Manipulaciones avanzadas de la apariencia del gráfico
Hasta ahora, hemos dejado que ggplot2 decida automáticamente la apariencia de los gráficos. Sin embargo, es probable que existan diversas razones para ajustar sus opciones, ya sea para mejorar la legibilidad, resaltar aspectos específicos de los datos o adaptarse a guías de estilo específicas. ggplot2 ofrece una amplia gama de herramientas de personalización que permiten refinar la apariencia de las visualizaciones. Comenzaremos con un gráfico simple e iremos aumentando progresivamente su complejidad.
Exploraremos cómo las características demográficas influyen en las relaciones urbanas analizando la población de las ciudades hermanadas. Este análisis se vincula con preguntas históricas más amplias sobre cómo el tamaño de la ciudad afecta su influencia internacional, cómo se desarrollan las jerarquías urbanas y cómo los patrones demográficos moldean los intercambios culturales y económicos. Enfoques similares podrían utilizarse para estudiar patrones de urbanización, el crecimiento de regiones metropolitanas o la relación entre el tamaño poblacional y el desarrollo económico.
Comenzaremos creando un gráfico de dispersión que relacione el tamaño de población de las ciudades de origen y destino. Un gráfico de dispersión es un gráfico que utiliza puntos para representar los valores de dos variables, relacionándolos en su punto de intersección. En este caso, cada punto del gráfico representará una pareja de ciudades hermanadas, con la coordenada x indicando el tamaño de población de la ciudad de origen y la coordenada y la población de la ciudad de destino. Si observamos una tendencia positiva clara —con puntos agrupados a lo largo de una línea diagonal desde la izquierda inferior hasta la superior derecha— esto sugerirá que las ciudades tienden a establecer relaciones con otras de tamaño de población similar.
Dado que eudata contiene 13,081 entradas, utilizar todas ellas daría un resultado difícilmente analizable. Por lo tanto, en este ejemplo, vamos a seleccionar una muestra aleatoria del 15% de las ciudades presentes en nuestros datos, utilizando la función slice_sample(). También es útil trabajar con el logaritmo natural del tamaño de población para superar la asimetría. Dado que estamos utilizando una selección aleatoria de datos, es necesario ‘establecer una semilla’ para garantizar la replicabilidad. Esto significa que si se ejecuta el código de nuevo, ggplot2 seleccionará de nuevo el mismo muestreo aleatorio. Esto se puede hacer mediante la función set.seed().
set.seed(123)
Ahora vamos a extraer una muestra aleatoria del 15% de las ciudades:
eudata.sample <- slice_sample(eudata, prop = 0.15)
Y creamos el gráfico con el siguiente código:
ggplot(data = eudata.sample,
aes(x = log(origenpoblacion), y = log(destinopoblacion))) +
geom_point()
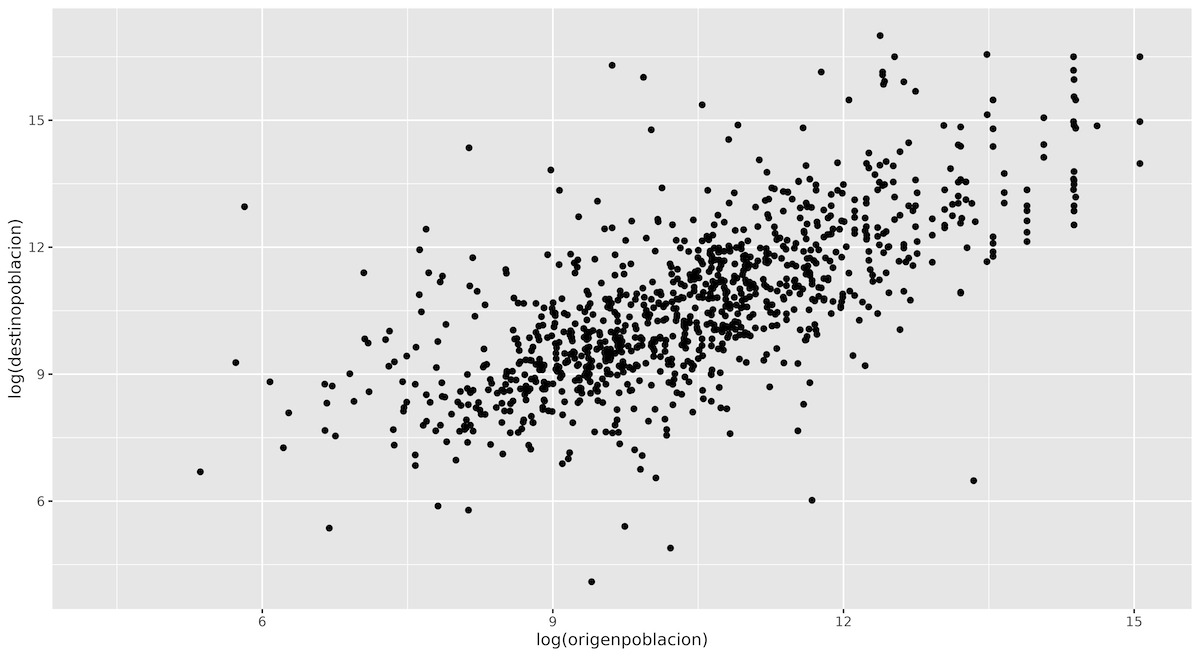
Figura 7. Gráfico de dispersión que compara la población (en logaritmo natural) en ciudades hermanadas seleccionadas al azar.
Ahora que hemos creado este gráfico básico, podemos empezar a jugar con su apariencia. ¿Por qué no empezar aplicando un tamaño fijo y un color a los puntos del gráfico? El siguiente código cambia el color de los puntos a un borgoña, utilizando el código hexadecimal #4B0000:
ggplot(data = eudata.sample,
aes(x = log(origenpoblacion), y = log(destinopoblacion))) +
geom_point(size = 0.8, color = "#4B0000")
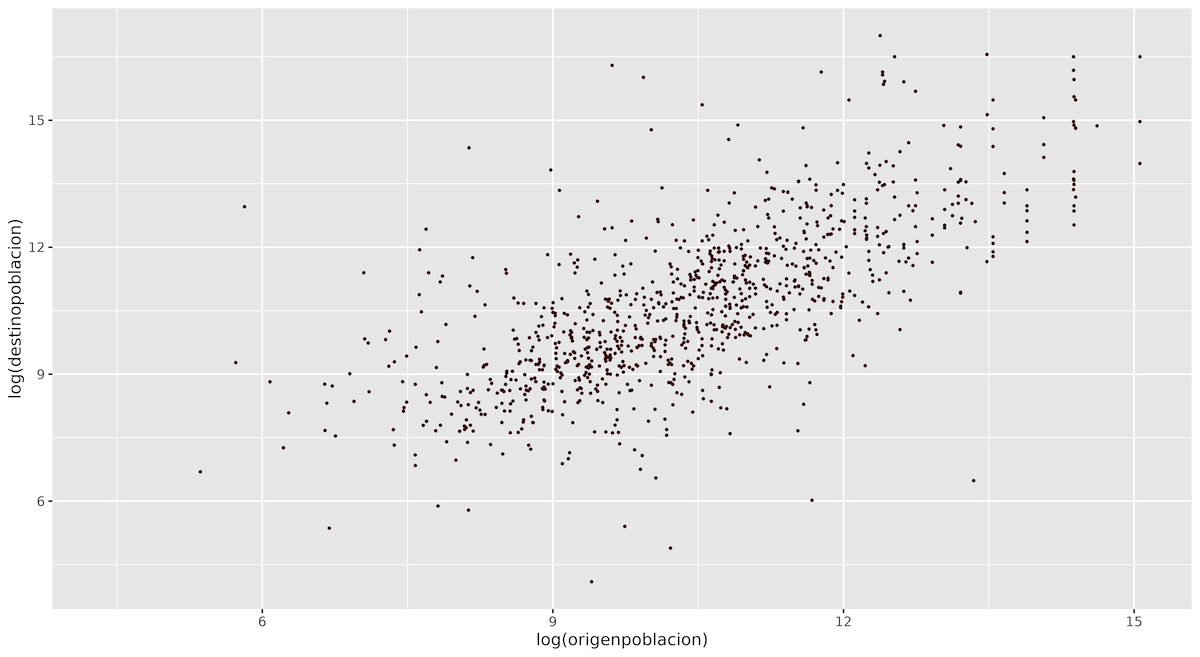
Figura 8. Cambiando el tamaño y el color de los puntos del gráfico de dispersión.
Para descubrir otros argumentos disponibles, puedes consultar la documentación de la función geom_point() (en inglés), o simplemente escribir ?geom_point en R.
Puedes seguir mejorando el gráfico agregando etiquetas de eje y una leyenda. La manipulación de ejes suele hacerse a través de las funciones de escala (scales) correspondientes, que trataremos más adelante. Sin embargo, cambiar las leyendas del gráfico es una acción muy común, y ggplot2 proporciona la función más breve labs() (en inglés), que se utiliza este propósito.
ggplot(data = eudata.sample,
aes(x = log(origenpoblacion), y = log(destinopoblacion))) +
geom_point(size = 0.8, color = "#4B0000") +
labs(title = "Población de la ciudad de origen y destino",
caption = "Datos: [www.wikidata.org](http://www.wikidata.org)",
x = "Población de la ciudad de origen (log)",
y = "Población de la ciudad destino (log)")
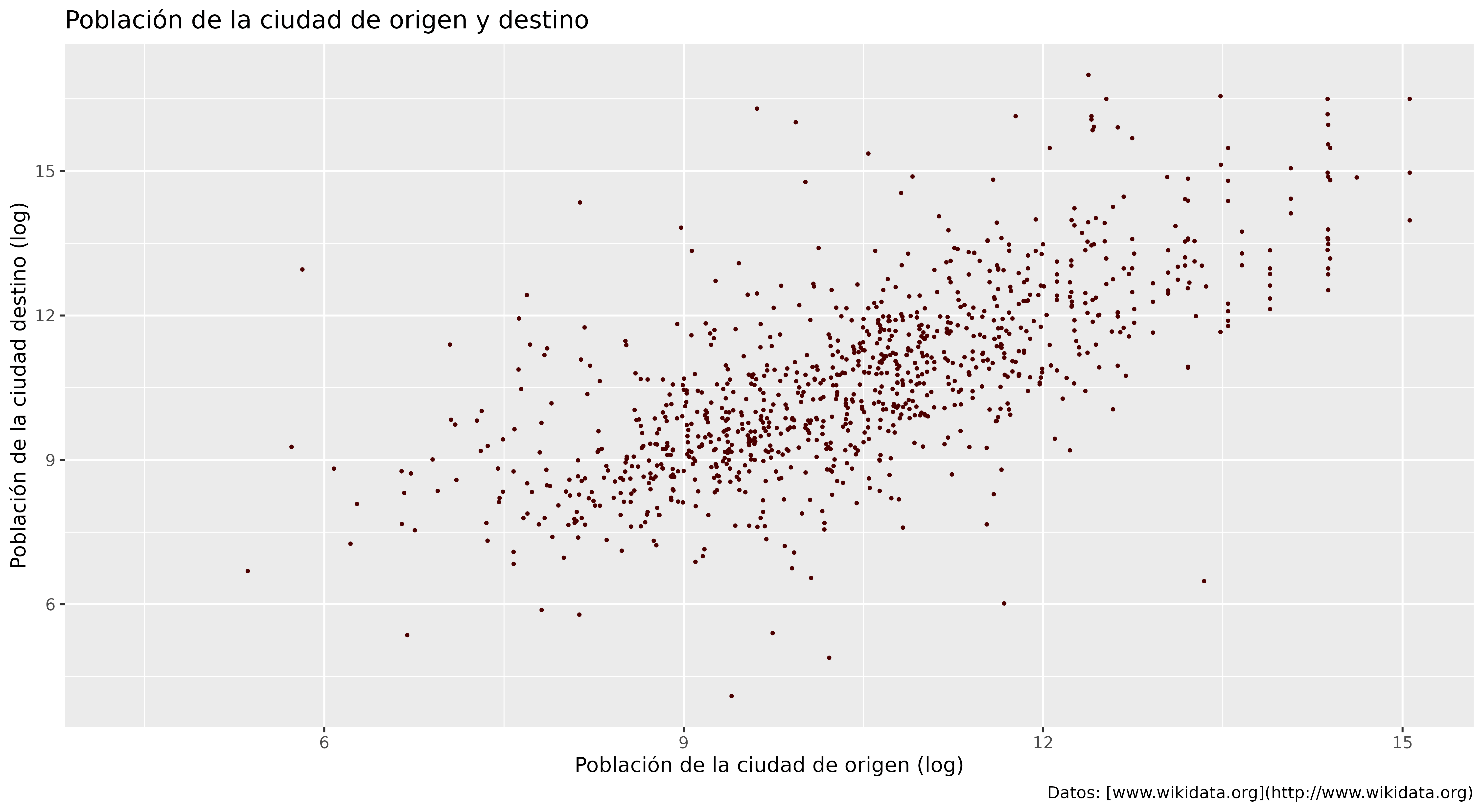
Figura 9. Títulos y etiquetas de ejes añadidas.
Una vez que estés satisfecho con tu gráfico, puedes guardarlo:
ggsave("eudata.png")
Para guardarlo como PDF, usa el siguiente comando:
ggsave("eudata.pdf")
Esto creará un archivo .png del último gráfico que hayas generado. La función ggsave() también incluye muchos parámetros ajustables (en inglés) (dpi, altura, ancho, formato y más).
A veces necesitarás enriquecer tu gráfico añadiendo información adicional, utilizando colores o formas diferentes. Esto es especialmente útil si deseas representar variables categóricas (en inglés) junto con las variables de interés principales. En el gráfico de dispersión (Figura 8), usamos valores estáticos para determinar el tamaño y el color de los puntos. Sin embargo, también podríamos mapear estas propiedades estéticas a columnas específicas de los datos, para visualizar sistemáticamente las diferentes categorías.
ggplot(data = eudata.sample,
aes(x = log(origenpoblacion), y = log(destinopoblacion))) +
geom_point(size = 0.8, alpha = 0.7, aes( color = tipopais )) +
labs(title = "Población de la ciudad de origen y destino",
caption = "Datos: [www.wikidata.org](http://www.wikidata.org)",
x = "Población de la ciudad de origen (log)",
y = "Población de la ciudad destino (log)")
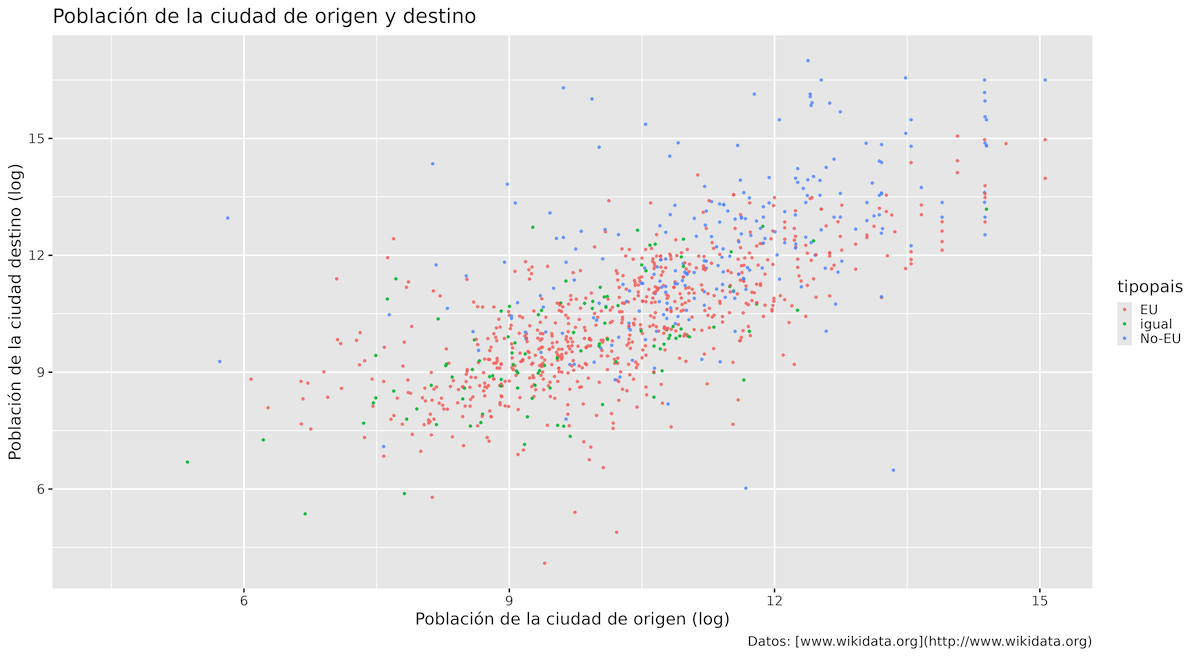
Figura 10. Uso de colores en gráficos de dispersión para visualizar diferentes tipos de países.
El código anterior tiene dos modificaciones importantes. En primer lugar, modificamos geom_point() agregando el argumento aes(color = tipopais). En segundo lugar, ya que había demasiados puntos superpuestos, agregamos el parámetro alpha para que tengan una transparencia del 70%. De nuevo, ggplot2 ha seleccionado colores y leyendas de serie predeterminados para el gráfico.
Scales: colores, leyendas y ejes
A continuación, exploraremos la función scale de ggplot2. Los scales pueden entenderse como una serie de reglas o un sistema de mapeo. Toman tus datos brutos (como números de población o nombres de países) y definen cómo deben representarse visualmente -qué color tendràn, dónde aparecerán en el gráfico, cuán grandes se mostrarán, etc. Sin scales, ggplot2 no sabría cómo traducir tus datos en una imagen significativa.
Tomemos nuestros propios datos como ejemplo. Cuando creas un gráfico, los scales se encargan de transformar tus datos brutos en elementos visuales. Especifican, por ejemplo, cómo se convierten los nombres de los países en colores diferentes (‘las ciudades francesas deben mostrarse en azul’), o cómo la distancia entre las ciudades se traduce en el tamaño de los puntos (‘las ciudades con poblaciones superiores a un millón deben mostrarse como puntos grandes’). Estas reglas garantizan que cada elemento de tus datos se muestre de manera consistente en toda tu visualización, lo que facilita a los lectores entender los patrones y relaciones que estás tratando de mostrar.
Los scales de ggplot2 siguen una convención de nomenclatura consistente en tres partes separadas por guiones bajos:
- El prefijo
scale. - El nombre de la escala que se modifica. Como se mencionó anteriormente, los estilos definen las propiedades visuales del gráfico que se mapean a los datos. Las escalas, por otro lado, controlan cómo esos mapeos de los estilos se traducen en representaciones visuales específicas. Esto incluye cómo los valores de los datos se traducen en colores o formas, y cómo se posicionan en las coordenadas x e y.
- El tipo de escala que se quiere aplicar (continua, discreta o los colores de las paletas brewer).
Antes de comenzar a agregar escalas, será útil almacenar el gráfico anterior en una variable p1: esta es una forma conveniente de crear diferentes versiones del mismo gráfico para variar solo ciertas partes de él.
p1 <- ggplot(data = eudata.sample,
aes(x = log(origenpoblacion), y = log(destinopoblacion))) +
geom_point(size = 0.8, alpha = 0.7, aes( color = tipopais )) +
labs(title = "Población de la ciudad de origen y destino",
caption = "Datos: [www.wikidata.org](http://www.wikidata.org)",
x = "Población de la ciudad de origen (log)",
y = "Población de la ciudad destino (log)")
Un uso común de los scales es cambiar los colores de un gráfico. Para especificar manualmente los colores que deseas, puedes utilizar la función scale_color_manual() y proporcionar un vector (en inglés) de valores de color, utilizando nombres de color definidos por R (en inglés) o sus códigos hexadecimales. La función scale_colour_manual() requiere un argumento obligatorio (en inglés), a saber, un vector de nombres de color. De esta manera, puedes crear gráficos con los colores que elijas (los nombres han de estar en inglés pues así están codificados en R y ggplot):
p1 +
scale_colour_manual(values = c("red", "blue", "green")) # rojo, azul y verde
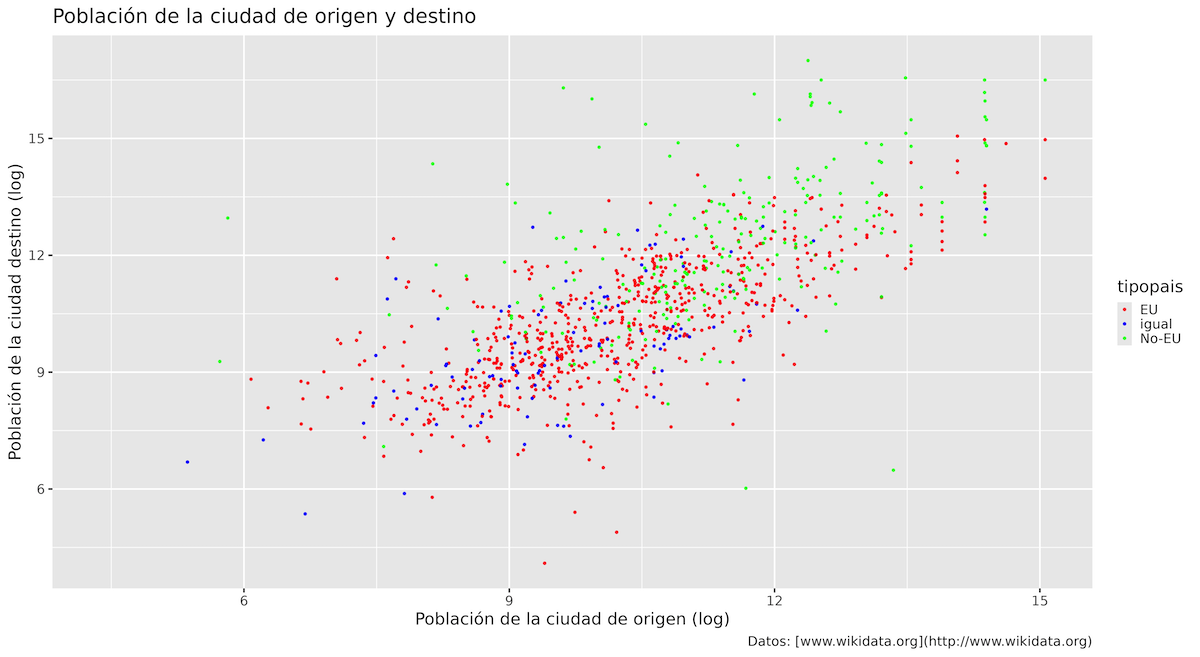
Figura 11. Uso de scale_colour_manual() para especificar los colores de los puntos.
Sin embargo, también puedes basarte en escalas de colores predefinidas, como las paletas de color brewer (en inglés). Es mejor utilizar estas cuando sea posible, porque elegir los colores adecuados para las visualizaciones es un problema muy complicado (por ejemplo, evitar colores que no son distinguibles para personas con visión deficiente). Afortunadamente, ggplot2 incluye la función scale_colour_brewer() ya integrada (en inglés).
p1 +
scale_colour_brewer(palette = "Dark2") # puedes probar otros como "Set1", "Accent", etc.
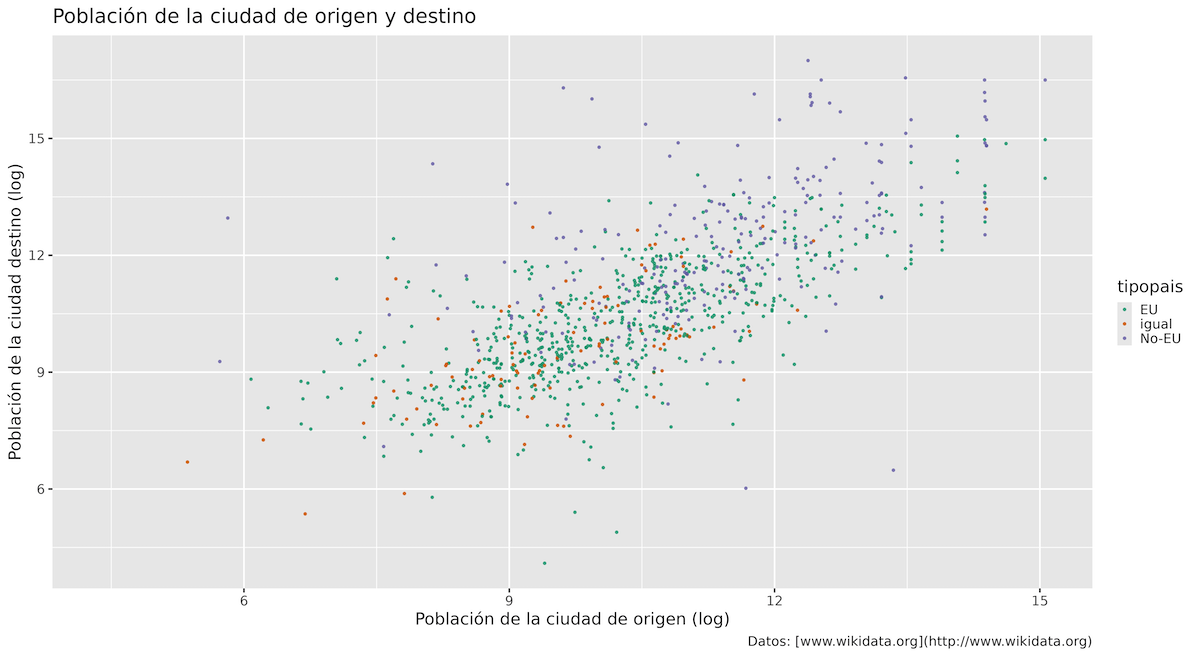
Figura 12. Uso de scale_colour_brewer() para cambiar el color de los puntos.
En el gráfico de dispersión que se muestra anteriormente, aprendimos cómo representar una variable cualitativa (o categórica) (tipopais) mediante tres colores diferentes. En el siguiente gráfico de dispersión, intentaremos representar una variable continua (distancia) –por ejemplo, la distancia entre ciudades de origen y destino- mediante intensidades de color variables. Intentemos simplemente mapear el color a la variable de distancia log(dist), que es la variable continua en este caso:
p2 <- ggplot(data = eudata.sample,
aes(x = log(origenpoblacion),y = log(destinopoblacion))) +
geom_point(size = 0.8, aes( color = log(dist) )) +
labs(title = "Población de la ciudad de origen y destino",
subtitle = "Coloreado según la distancia entre ciudades",
caption = "Datos: [www.wikidata.org](http://www.wikidata.org)",
x = "Población de la ciudad de origen (log)",
y = "Población de la ciudad destino (log)")
p2
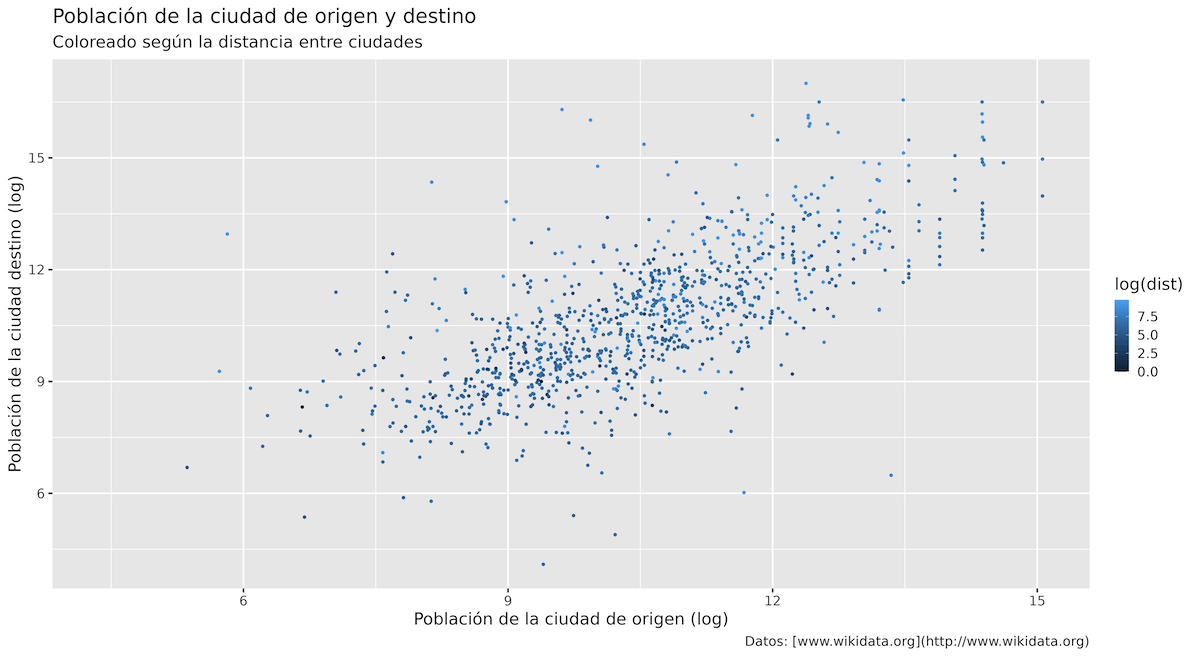
Figura 13. Mapeando los colores a la distancia entre las ciudades.
Inmediatamente se nota que este código no ha producido la visualización más intuitiva:
-
De manera predeterminada, ggplot2 utiliza una gradiente de color azul para las variables continuas cuando no se especifica un color específico.
-
La escala predeterminada también es contraintuitiva, ya que las distancias más cortas se representan por un azul más oscuro, no más claro (que sería lo que esperaríamos).
En este ejemplo, de nuevo, utilizar un scale proporciona las herramientas para corregir estos valores predeterminados y crear visualizaciones que comuniquen los datos subyacentes de forma más efectiva y precisa. Para representar una variable continua, las escalas de color graduadas – es decir, ‘continuas’ – asignan colores a los valores basándose en una transición suave entre tonos o matices. Esto permite una representación precisa de la variable continua, ya que el cambio de color gradual corresponde al cambio de valor de la variable. Utilizar una escala graduada te permite visualizar la distribución de valores e identificar patrones o tendencias en los datos.
Hay diferentes métodos para crear escalas graduadas en ggplot2 (en inglés). Para nuestro propósito, usaremos la función scale_colour_gradient(). Esto te permite asignar colores específicos a los mínimos y máximos valores de la variable continua. ggplot2 luego interpola automáticamente los colores para los valores intermedios en función del gradiente elegido.
Puedes trabajar con el objeto p2 creado anteriormente y utilizar el operador + para modificarlo. Ya habías mapeado la variable dist (distancia entre ciudades) al color utilizando color = dist dentro de la función aes(). Ahora, agrega la función scale_colour_gradient() para personalizar el gradiente de colores. En el siguiente código, establecemos el color para el valor más bajo de la variable dist como blanco y el valor más alto como un rojo oscuro (#4B0000). Esto significa que los tonos más claros de rojo representan distancias cortas, mientras que los tonos más oscuros representan distancias largas.
p2 +
scale_colour_gradient(low = "white", high = "red3") # 'white' por blanco en inglés y red3 es una de las tonalidades de rojo
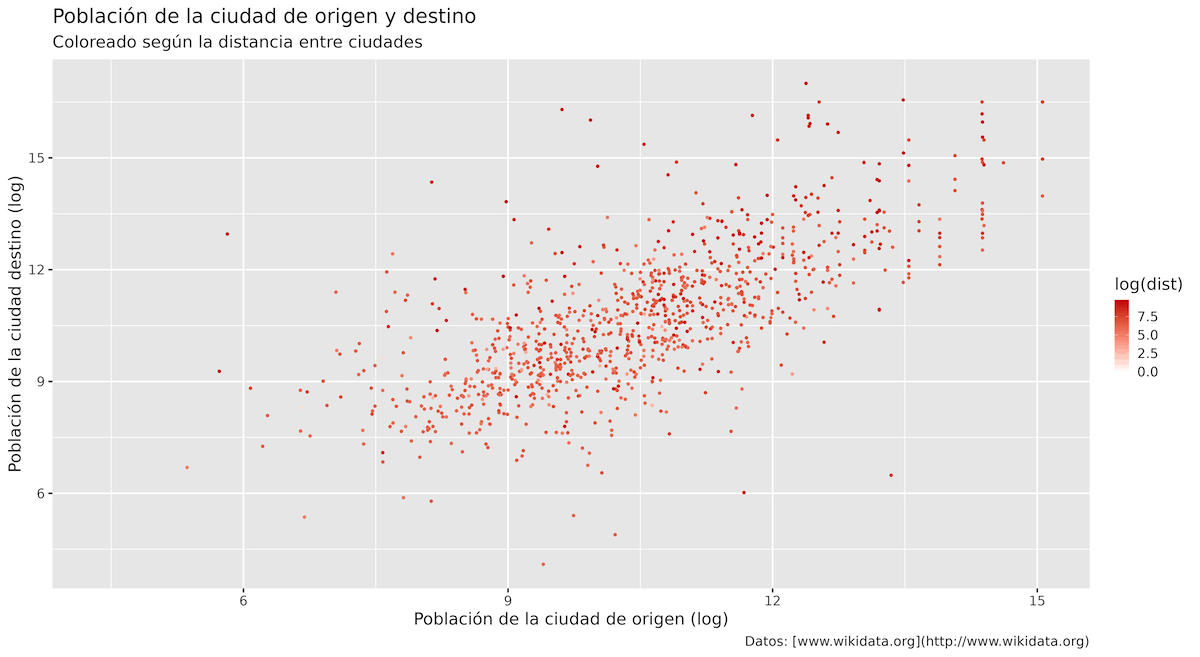
Figura 14. Tamaño de la población de la ciudad de origen y la ciudad de destino coloreado según la distancia entre ambas usando scale_colour_gradient().
¿Qué podemos inferir de este gráfico? En cierto modo, parece que las ciudades más pequeñas tienden a establecer relaciones con ciudades que son más cercanas. En las secciones anteriores, examinaste la distribución de las distancias entre las ciudades hermanadas utilizando un gráfico de histograma y un gráfico de ECDF. Estas visualizaciones revelaron que las relaciones entre ciudades se caracterizan principalmente por distancias cortas, sobre todo dentro de un radio de 500 a 1000 kilómetros. Comparar los hallazgos en diferentes visualizaciones puede mejorar nuestra comprensión de los patrones observados y resaltar la importancia de considerar ciertos factores clave.
A partir de estas consideraciones, ahora modifiquemos la leyenda del gráfico de dispersión. Personalizarla mejorará la claridad, haciendo que el gráfico sea más fácil de interpretar para los lectores.
Puedes modificar la leyenda alterando el parámetro guide dentro de la función scale_colour_gradient(). El parámetro guide especifica el título, la posición y la orientación de la leyenda. Aquí también se utilizará la función guide_colorbar() para crear una leyenda de barra que represente las distancias entre las ciudades con una gama de colores.
p2 <- p2 +
scale_colour_gradient(low = "white",
high = "red3",
guide = guide_colorbar(title = "Distancia en log(kms)", direction = "horizontal", title.position = "top"))
p2
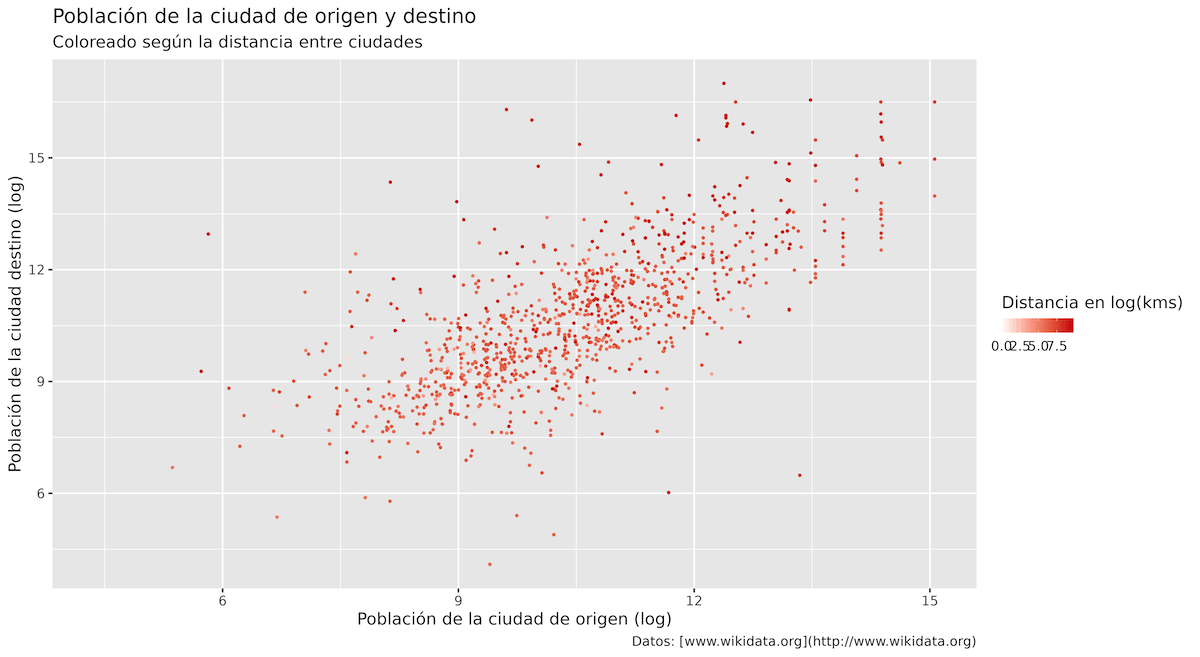
Figura 15. Modificando el título y añadiendo una barra de color.
Facetando un gráfico
Otra gran característica de ggplot2 es que permite dividir tus datos en diferentes gráficos según una variable determinada. En ggplot2, este proceso se conoce como facetting (en inglés). La función más sencilla para esta tarea es facet_wrap(), pero también puedes explorar la función más completa facet_grid() (en inglés) para más opciones.
Anteriormente, habíamos creado un gráfico que resaltaba si las ciudades de destino estaban dentro del mismo país que la ciudad de origen, en un país diferente pero de la UE o en un país no UE. Utilizando el tibble eudata.porcentaje.pais, podrías dividir este gráfico agregando facet_wrap() según los diferentes países de origen:
ggplot(eudata.porcentaje.pais, aes(x = tipopais, y = porcentaje)) +
geom_bar(stat = "identity") +
facet_wrap(~origenpais)
El operador de virgulilla (~) se utiliza comúnmente en fórmulas de R. En este caso, indica qué variable debe utilizar ggplot2 para definir la estructura de los paneles. En otras palabras, la fórmula ~origenpais le dice a ggplot2 que divida los datos según el valor de la variable origenpais, y cree un gráfico separado para representar cada valor (en este caso, cada país). El gráfico resultante mostrará los gráficos de barras en paneles separados:
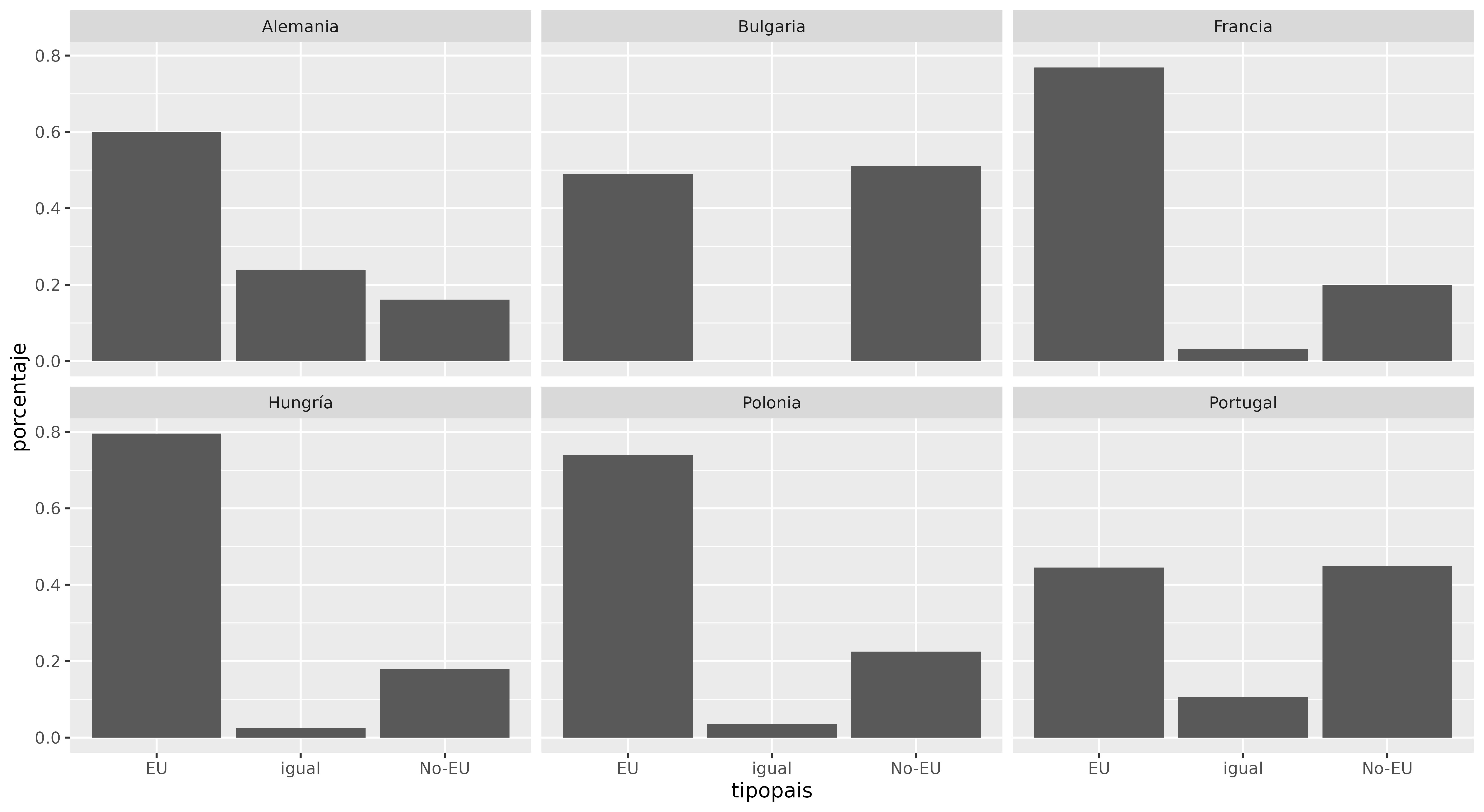
Figura 16. Faceteando el gráfico con facet_wrap().
Temas: modificando elementos estáticos
Dado que la apariencia de un gráfico es crucial para comunicar diferentes aspectos de manera efectiva, ggplot2 proporciona temas que permiten personalizar elementos adicionales. Estos temas controlan los elementos no estrictamente relacionados con los datos, sino cuestiones como el color de fondo y los estilos de fuente.
Establecer un tema es muy sencillo: solo aplícalo como una capa nueva usando el operador +. Aquí mostramos un tema blanco y negro:
p3 <- ggplot(eudata.porcentaje.pais, aes(x = tipopais, y = porcentaje)) +
geom_bar(stat = "identity") +
facet_wrap(~origenpais)
p3 + theme_bw() # _bw se corresponde al inglés black/white (negro/blanco)
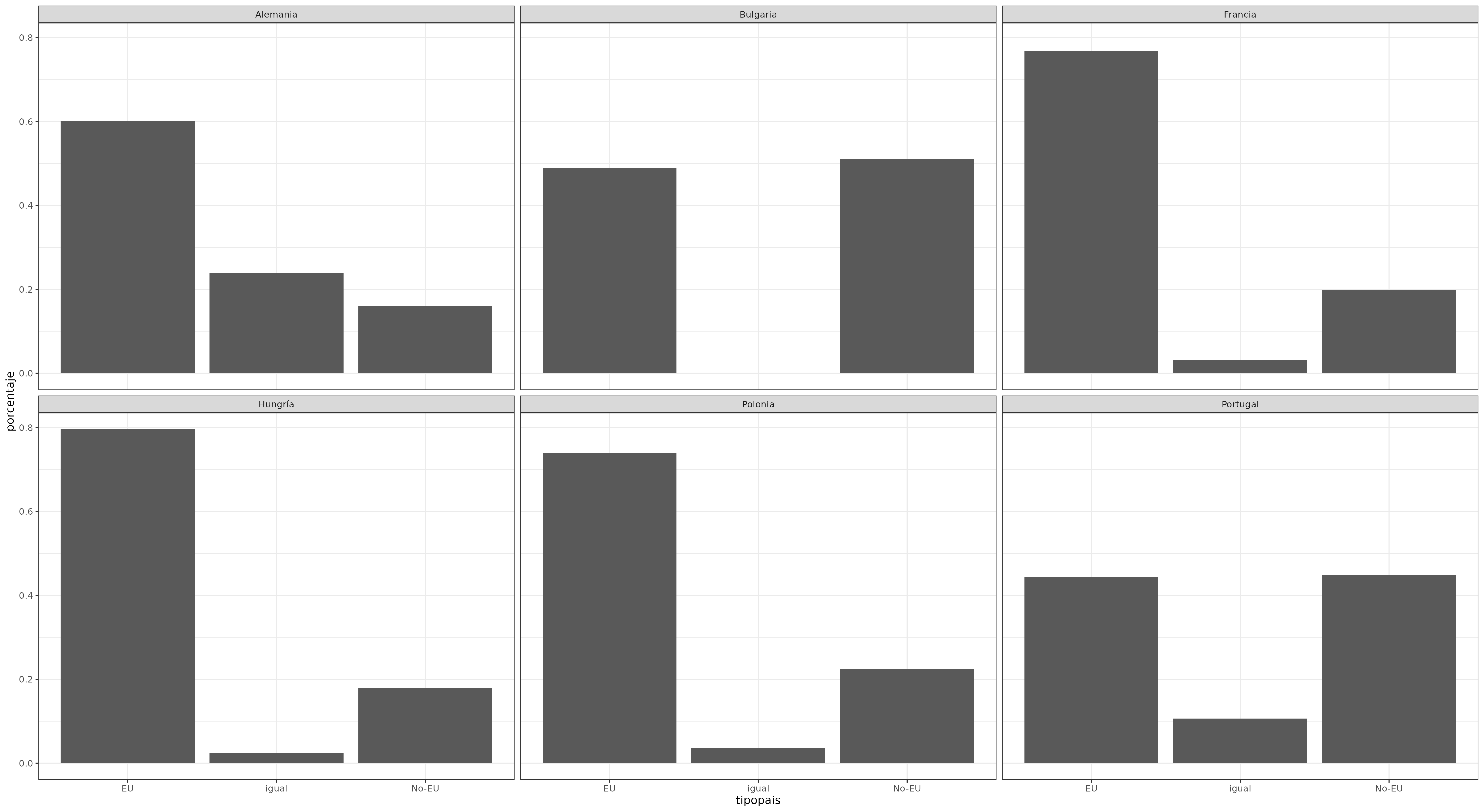
Figura 17. Cambiando elementos estáticos por medio de theme_bw().
También puedes instalar varios paquetes que proporcionan temas adicionales, como ggthemes (en inglés) o ggtech (en inglés). En estos encontrarás, por ejemplo, theme_excel (replicando los clásicos gráficos de Excel) y theme_wsj (basado en los gráficos de The Wall Street Journal (en inglés)). El beneficio de utilizar temas de ggplot2 para replicar estos estilos reconocibles no solo es la simplicidad, sino también el hecho de que ggplot2 tiene en cuenta automáticamente el lenguaje gráfico cuando mapea tus datos a elementos del gráfico.
Para replicar los gráficos creados por The Wall Street Journal, puedes escribir lo siguiente:
install.packages("ggthemes")
library(ggthemes)
p3 + theme_wsj()
Figura 18. Cambiando elementos estáticos usando el tema de The Wall Street Journal.
Extendiendo ggplot2 con otros paquetes
Una de las fortalezas de ggplot2 es su amplia colección de extensiones (en inglés) que pueden ayudar a enriquecer tu análisis con visualizaciones especializadas como gráficos de red (útiles para mostrar relaciones entre ciudades, por ejemplo), series de tiempo (para rastrear cambios demográficos a lo largo del tiempo), y gráficos de ridgeline, también llamados gráficos de cresta en español (para comparar distribuciones poblacionales en diferentes áreas urbanas).
Vamos a explorar un ejemplo que muestra un paquete de extensión de ggplot2 capaz de crear gráficos más avanzados e impactantes. En este caso, vamos a crear un gráfico de ridgeline (en inglés) – también conocido como ‘joyplot’ – diseñado para visualizar los cambios en las distribuciones a lo largo del tiempo, en distintas categorías. Los gráficos de ridgeline son particularmente efectivos para comparar múltiples distribuciones de manera compacta y atractiva.
Para crear un gráfico de ridgeline, necesitarás el paquete ggridges (uno de muchos paquetes de extensión de ggplot2). Esto añade una capa llamada geom_density_ridges() y un tema llamado theme_ridges(), que amplían las posibilidades de crear gráficos en R.
Esta codificación es lo suficientemente simple (de nuevo, utilizando una transformación logarítmica debido a la asimetría en la distribución de los datos):
install.packages("ggridges")
library(ggridges)
ggplot(eudata, aes(x=log(origenpoblacion), y = origenpais)) +
geom_density_ridges() +
theme_ridges() +
labs(title = "Población (log) de las ciudades de origen",
caption = "Datos: [www.wikidata.org](http://www.wikidata.org)",
x = "Población (log)",
y = "País")
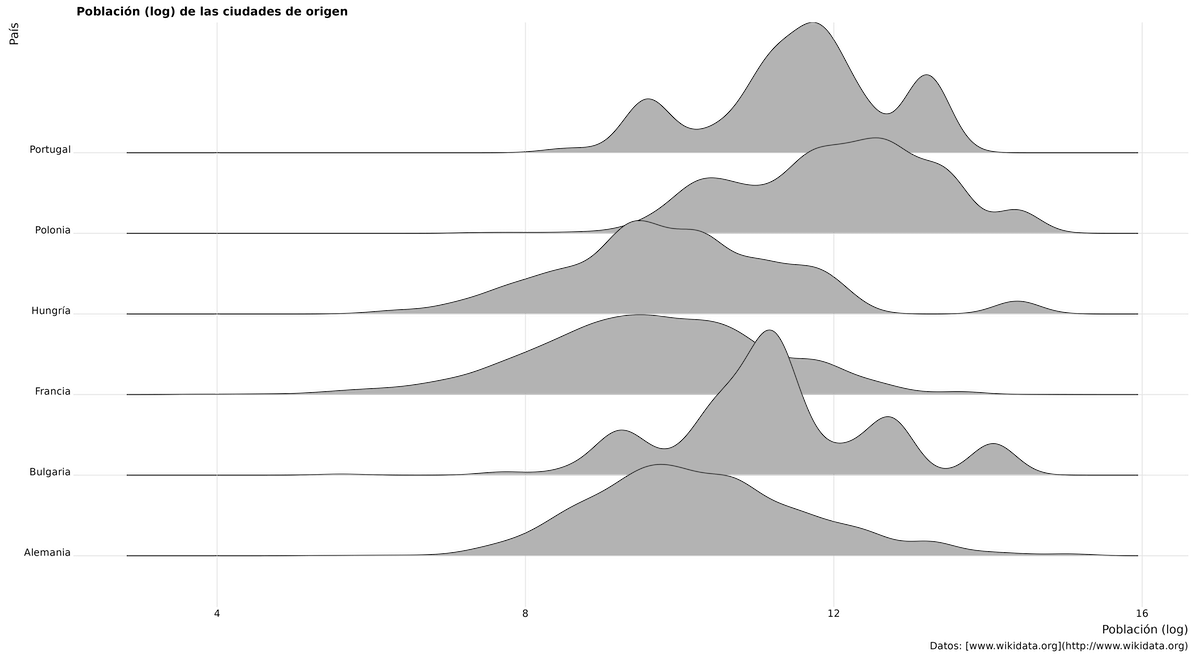
Figure 19. Extendiendo ggplot2 con el paquete ggridges.
Esta visualización de las distribuciones de la población muestra cómo varían los patrones demográficos urbanos según el país. Por ejemplo, Polonia, Portugal y Bulgaria presentan perfiles demográficos distintos, dado que sus ciudades tienden a tener tamaños de población más grandes, como se indica en los picos de los respectivos gráficos de densidad.
Conclusión
A través del análisis de las relaciones de hermanamiento de las ciudades de la Unión Europea utilizando ggplot2 y sus extensiones, hemos demostrado cómo diferentes técnicas de visualización pueden revelar patrones en las redes urbanas y características demográficas. El conjunto de datos permitió identificar información relevante que merece mayor investigación: las ciudades tienden a crear relaciones dentro de una distancia entre 500 y 1000 km; los países con los que se asocian varían significativamente con una preferencia por alianzas nacionales frente a internacionales, y el tamaño de la población juega un papel en la formación de estas relaciones.
Sin embargo, esto es solo la punta del iceberg de las posibilidades de ggplot2. Con un extenso ecosistema de extensiones y paquetes, ggplot2 ofrece oportunidades casi infinitas para la personalización y la adaptación a necesidades específicas a la hora de visualizar datos. Si trabajas con datos de series temporales, con gráficos de redes o con información geoespacial, es probable que una extensión de ggplot2 pueda ayudarte a crear visualizaciones atractivas e informativas. Al seguir explorando y trabajando con ggplot2, recuerda que la visualización efectiva de los datos es un proceso iterativo que requiere experimentación, refinamiento y una comprensión aguda de tu audiencia y de tus objetivos de comunicación. Si dominas bien los principios y técnicas que cubre esta lección, estarás bien equipado para crear visualizaciones impactantes que iluminen las historias ocultas en tus datos.
Recursos adicionales
Existe una variedad de recursos de aprendizaje y documentación disponibles en línea que pueden resultar útiles. Sin embargo, el material en español es muy limitado, por lo que esperamos que esta lección ayude a cubrir esa brecha. Los siguientes recursos están en inglés, a menos que se indique lo contrario.
-
El sitio oficial de ggplot2. Sin embargo, puedes consultar este recurso en español: 30 Conceptos básicos de ggplot en EpiRhandbook en español
-
Los libros de Hadley Wickham
ggplot2:Elegant Graphics for Data Analysis (3e), en inglés, y R para el análisis de datos, en español. -
El trabajo original de Hadley Wickham sobre la gramática de gráficos.
-
El libro original de Leland Wilkson The Grammar of Graphics.
-
La tutoría de Selva Prabhakaran en r-statistics.co.
-
El video de Data Science Dojo Data Visualization with ggplot2 .
-
La página oficial de extensiones de ggplot2 y su galería.
-
El libro Cookbook for R (basado en la obra de Winston Chang R Graphics Cookbook: Practical Recipes for Visualizing Data.
-
La chuleta oficial de R con traducciones al español disponibles.
-
La página de escalas de gradiente.
Notas
-
Para una referencia en español, puedes consultar el libro Gramática de las gráficas. Pistas para mejorar las representaciones de datos de Joaquín Sevilla Moróder (2005) https://files01.core.ac.uk/download/pdf/33747372.pdf ↩
-
Esta traducción es ‘un proyecto colaborativo de la comunidad de R de Latinoamérica, que tiene por objetivo hacer R más accesible en la región’ https://es.r4ds.hadley.nz/#sobre-la-traducción. Su versión original tiene una segunda edición que puedes consultar también online y en abierto en R for Data Science (2e) ↩